【数据研发】OLTP与OLAP的概念与比较

【数据研发】OLTP与OLAP的概念与比较
6YoungOLTP与OLAP概念
在业务数据处理的早期,对数据库的写入往往对应着发生了一次真实的商业交易:银行转账(要从A账户扣100,并向B账户加100),支付工资等。后续随着数据库的应用越来越广泛,开始用来存储博客的评论、游戏进度等等,但是其访问模式没有变化,主要是执行基本的事务处理,对应于数据库记录的增删改查。这种访问模式被称为:联机事务处理(On-line transaction processing,OLTP)。
现在,数据库也开始越来越多地用于数据分析,通常,用于分析的查询需要扫描大量的数据(比如一个月,一个季度等),并聚合得到统计数据,帮助公司管理层做出更好的决策(business intelligence,商业智能 BI),区别于联机事务处理,这种侧重于分析场景的访问模式被称为:联机分析处理(On-Line Analytical Processing,OLAP)。
起初,同一个数据库既用于事务处理,也用于分析查询(例如,Mysql)。但是随着数据量的爆炸式增长,在90年代初,各个公司出现了一种 OLTP 与 OLAP 场景分离的趋势,即用专门的数据库来支撑决策分析的 OLAP场景任务。这个专门的数据库也被称为数据仓库。
| OLTP vs. OLAP 比较项 | OLTP | OLAP |
|---|---|---|
| 查询模式 | 简单的事务:每个查询返回少量记录,往往按照键(索引)来查询 | 复杂的聚合分析:往往聚合大量的记录 |
| 写入模式 | 随机访问,低延迟写入(写入数据主要为用户输入) | 顺序写,批量导入 |
| 使用用户 | 应用开发,终端用户的日常事务处理 | 内部分析人员,用于决策支持 |
| 设计方向 | 面向应用 | 面向主题 |
| 数据内容 | 当前最新的明细记录 | 历史的,聚集的,多维的,集成的数据 |
| 数据量级 | GB到TB | TB到PB |
| 读写占比 | 读:60%,写:40% | 读:95%,写:5% |
数据仓库
一个企业往往有几十个业务数据库,例如,商品库、交易库、售后库、财务库、物流库、促销库等等,这些库中的每一个都相对独立,并且都是一个很复杂的业务系统模块,每个库都有一个或者多个业务开发团队来维护。这些 OLTP系统具有高可用和低延迟的特点,对App或者Web系统的运营至关重要。一般情况下,业务系统不会允许数据分析的查询sql直接运行在业务库上,因为分析类sql往往需要扫描大量数据,会严重影响数据库的性能。为此,业界引入了数据仓库,专门来处理各种分析式查询,数仓中包含了公司中所有的有分析价值的数据,经过ETL过程,抽取业务系统的数据清洗、转换、然后加载到数仓中,形成易于分析的数据。ETL过程如下图所示:
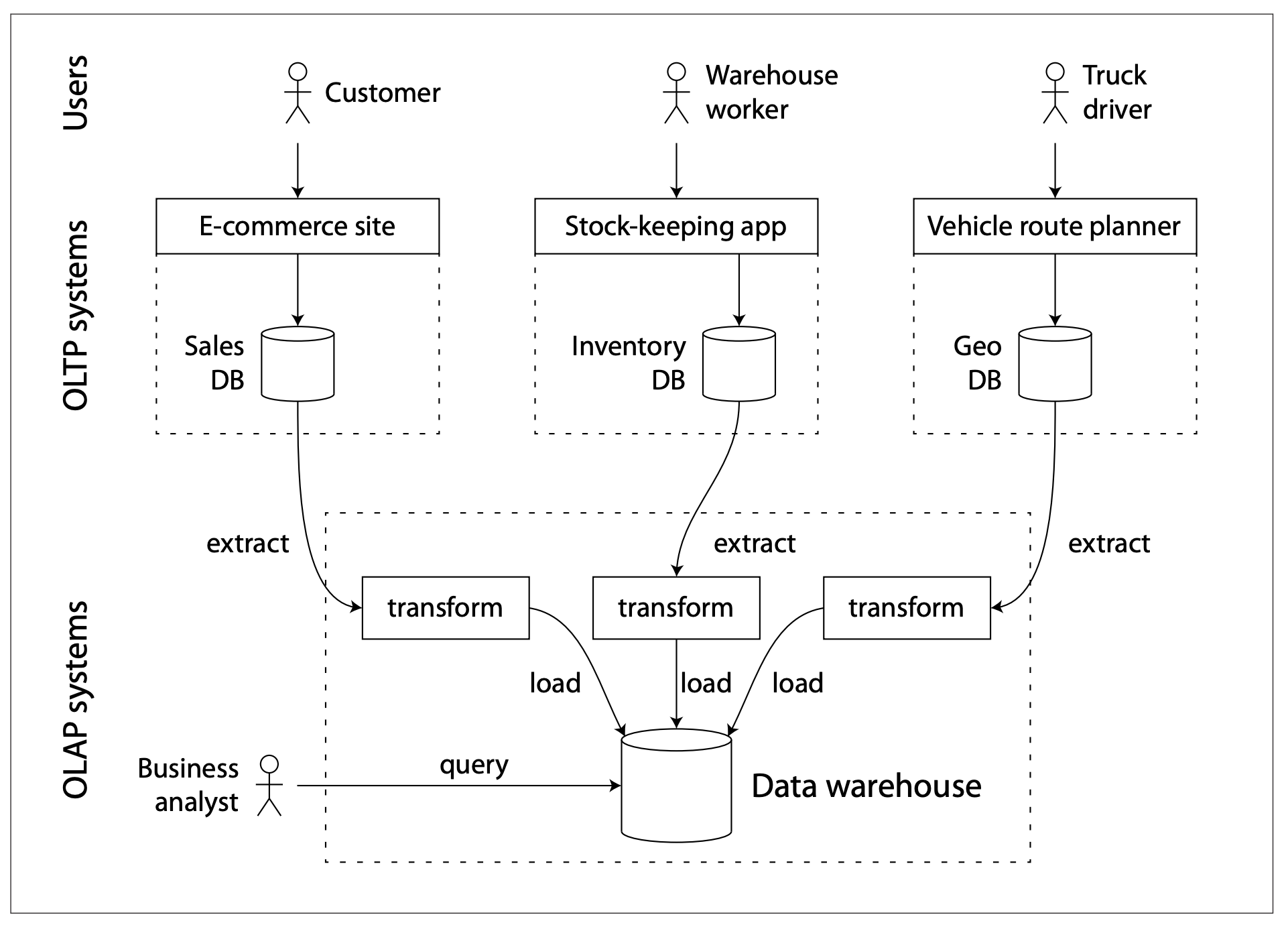
目前,数仓已经广泛存在于大厂中,并对业务的发展决策起到不可替代的作用,但是在小公司中可能见不到数仓。造成这个现象的主要原因是小公司业务场景单一,业务规模很小,数据量很小,小到可以在 Mysql数据库中直接执行分析类查询也可以,甚至可以用Excel来分析数据。
星型模型和雪花模型
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,大致可以分为星型模型和雪花模型。
星型模型
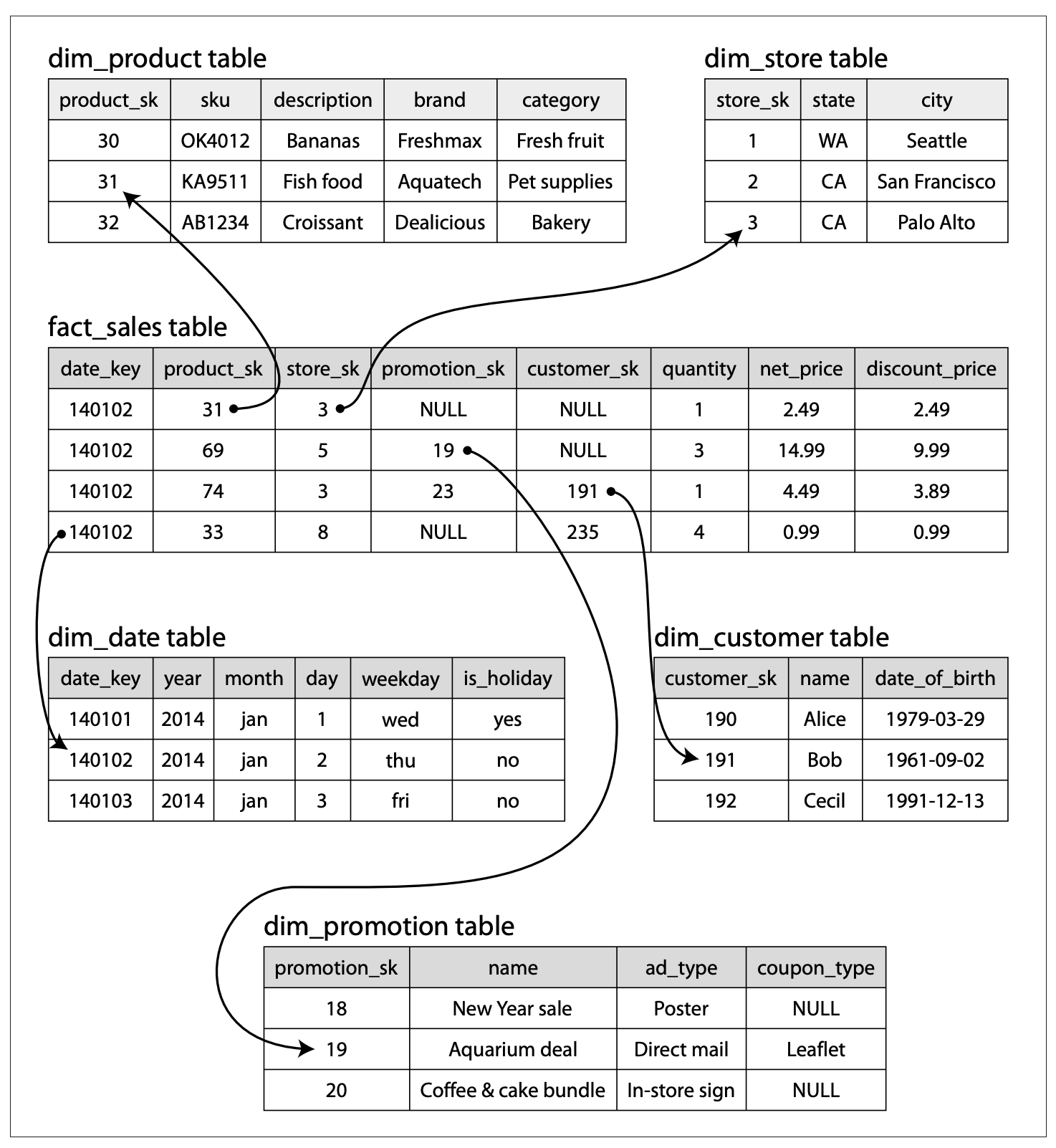
上图是典型的电商场景的数据仓库,fact_sales 表是事实表。事实表的每一行代表了在特定时间发生的事件(这里的每一行代表了用户购买的商品),这也会意味着事实表会很大。事实表的某些列是指标,例如,net_price;某些列是维度,例如,date_key,product_sk,维度列引用的表称为维度表。维度表代表了事件中的谁,在什么时间,什么地方发生了事件。
在上图的示例中,dim_product是一个维度表,dim_product表中存储了商品SKU、品类、品牌,以及产地等商品固有属性信息;日期维表存储了当前日期的所在年份、周、月份,以及是否是节假日等,以便于统计节假日和非节假日的销售情况……,从上图可以发现,维表均链接在事实表上,事实表位于中间,被维表所包围,整个图就像星星一样。因此这种模型组织形式,称为“星型模型”。星型模型,是一种反规范化的数据组织形式(一般都要对数据进行预处理,相同实体的属性退化到一张维表里,维度退化),形成一张宽表,数据有一定的冗余,但是使用起来会非常简单,因为只需要将事实表跟各种维度组合起来,再聚合就可以满足大部分分析场景的需要了。
雪花模型
雪花模型是星型模型的一个变体,其中维度进一步分解为子维度。比如 dim_product维表中的 brand字段和 category字段,可以再拆分成 dim_brand维表和 dim_category维表。它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,去除了数据冗余,但是在分析数据的时候,需要 join的表比较多,所以查询性能不一定比星型模型要好。
什么时候适合用雪花模型?
《数据仓库工具箱》中,提出了比较适合用雪花模型的三个例子:
- 用户维表数据量较大,其中,有80%的用户记录是匿名访问者,仅包含少数信息,20%是注册的用户,且注册用户都有很详细的信息。
- 一个金融产品的维度表,金融产品有不同的分类,银行类的、保险类的等,每种不同类型的产品都有自己的一系列特殊的属性。
- 多个事业部共用的日期维度表,但是每个事业线的财政周期不同,节假日不同。
OLAP数仓与OLTP传统数据库的比较
OLTP数据库的一般特点:
- 实时性要求很高,延迟一般在毫秒级别,一般用于交互式系统,比如买票,点击支付之后,就希望得到系统反馈是否购买成功,较长时间的等待会显著影响用户的体验。
- 数据量不大,生产库为了保持最佳性能,一般只保留最近半年甚至更短时间的数据,历史数据会进行归档处理。
- 一次操作只会查询/插入/更改少量的数据,比如用户A购买成功了2件商品,只会对少数几条进行插入或者更新购买状态操作。
- 支持高并发,比如双11大促秒杀活动等,需要支撑几十万甚至上百万的QPS请求。
- 功能模块相对单一,核心满足各个模块的业务功能使用。
- 对事务有很好地支持。
OLAP数仓的一般特点:
- 实时性要求不是很高,实时场景大部分为分钟级,离线场景一般为天级。
- 数据量很大,离线场景会统计汇总月,季度,甚至是年的历史数据,实时场景一般为日,周,月的历史数据。
- 通过数据提供决策支持,所以查询一般是根据各种维度进行查询,往往需要跨不同的业务库进行分析。









