【编程学习】大数据背景下的SQL效率优化

【编程学习】大数据背景下的SQL效率优化
6YoungDistinct优化
应该如何优化?
Hive底层使用MapReduce作为实际计算框架
假设当前有个去重任务SELECT COUNT( DISTINCT id ) FROM TABLE WHERE ...
由于引入了DISTINCT,因此在Map阶段无法利用combine对输出结果去重,必须将id作为Key输出,在Reduce阶段再对来自于不同Map Task、相同Key的结果进行去重,计入最终统计值。
该作业运行时的Reduce Task个数为1,对于统计大数据量时,这会导致最终Map的全部输出由单个的ReduceTask处理。这唯一的Reduce Task需要Shuffle大量的数据,并且进行排序聚合等处理,这使得它成为整个作业的IO和运算瓶颈。但是,如果显式地增大Reduce Task个数来提高Reduce阶段的并发set mapred.reduce.tasks=100;调整后我们会发现这一参数并没有影响实际Reduce Task个数。因为Hive在处理COUNT这种“全聚合(full aggregates)”计算时,它会忽略用户指定的Reduce Task数,而强制使用1。
鉴于此,可以采用变通的方法来绕过这一限制:SELECT COUNT(*) FROM (SELECT DISTINCT id FROM TABLE WHERE … ) t;;此时子查询的distinct不会受到reduce限制,会使用多个reduce实现去重;外部count查询的map-reduce的输入量就很少了,最后再用一个reduce进行count(*)也不会造成性能瓶颈。
此外,使用SELECT COUNT(*) FROM (SELECT id FROM TABLE WHERE … GROUP BY id) t;也是可行的,原理都是通过降低reduce的负载来实现提高效率。
数据倾斜
但是这样又回产生数据倾斜的问题,group by可以设定参数实现自动的解决数据倾斜:
JOB1 .第一个作业会进行预处理,将数据进行预聚合,并随机分发到 不同的 Reducer 中。
Map流程 : 会生成两个job来执行group by,第一个job中,各个map是平均读取分片的,在map阶段对这个分片中的数据根据group by 的key进行局部聚合操作,这里就相当于Combiner操作。
Shuffle流程:在第一次的job中,map输出的结果随机分区,这样就可以平均分到reduce中
Reduce流程: 在第一次的job中,reduce中按照group by的key进行分组后聚合,这样就在各个reduce中又进行了一次局部的聚合。
JOB2.读取上一个阶段MR的输出作为Map输入,并局部聚合。按照key分区,将数据分发到 Reduce 中,进行统计。
Map流程 : 因为第一个job中分区是随机的,所有reduce结果的数据的key也是随机的,所以第二个job的map读取的数据也是随机的key,所以第二个map中不存在数据倾斜的问题。
在第二个job的map中,也会进行一次局部聚合。
Shuffle流程 : 第二个job中分区是按照group by的key分区的,这个地方就保证了整体的group by没有问题,相同的key分到了同一个reduce中。
Reduce流程 :经过前面几个聚合的局部聚合,这个时候的数据量已经大大减少了,在最后一个reduce里进行最后的整体聚合。
Join操作的优化
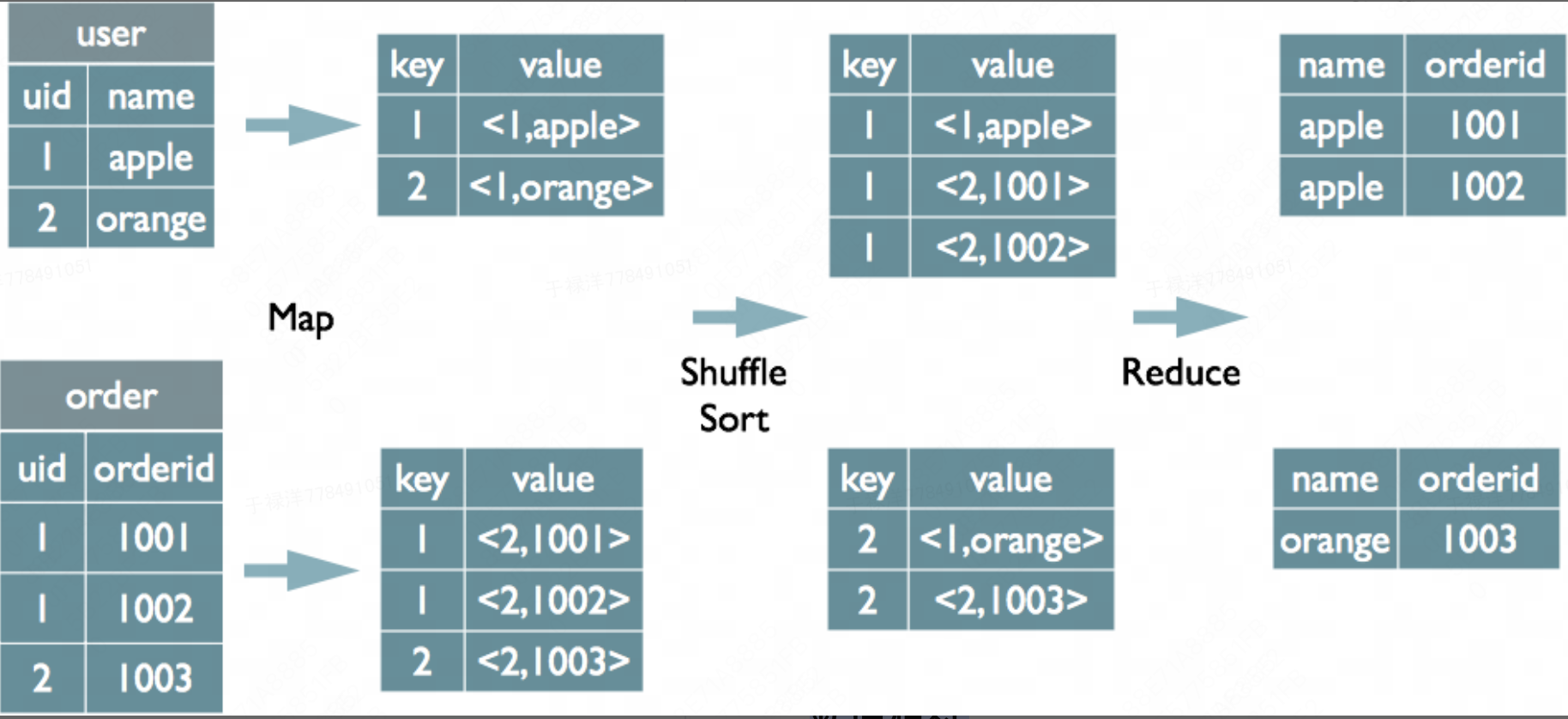
common join
Map阶段:读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;按照key进行排序
Shuffle阶段:根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
Reduce阶段:根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
mapjoin
MapJoin通常用于一个很小的表和一个大表进行join的场景(小表join小表也行,但是没必要)
- 将小的那份数据给每个MapTask的内存都放一份完整的数据,大的数据每个部分都可以与小数据的完整数据进行join
- 底层不需要经过shuffle,需要占用内存空间存放小的数据文件
在map端产生join, mapJoin的主要意思就是,当链接的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小的table直接放到内存中去,然后再对比较大的表格进行map操作。join就发生在map操作的时候,每当扫描一个大的table中的数据,就要去去查看小表的数据,哪条与之相符,继而进行连接。这里的join并不会涉及reduce操作。map端join的优势就是在于没有shuffle和省了网络传输。
数据倾斜
- 可以限制不处理空值
- 给空值添加随机数
减少Job数之用group by 代替join
Group by 不仅能够提高distinct的效率,还能提高join的效率。
在实际开发过程中也发现,一些实现思路会导致生成多余的Job而显得不够高效。比如这个需求:查询某网站日志中访问过页面a和页面b的用户数量。低效的思路是面向明细的,先取出看过页面a的用户,再取出看过页面b的用户,然后取交集,代码如下:
减少job-优化前
1 | select count(*) |
这样一来,就要产生2个求子查询的Job,一个用于关联的Job,还有一个计数的Job,一共有4个Job。
但是我们直接用面向统计的方法去计算的话(也就是用group by替代join),则会更加符合M/R的模式,而且生成了一个完全不带子查询的sql,只需要用一个Job就能跑完:
减少job-优化后
1 | select count(*) |
第一种查询方法符合思考问题的直觉,是工程师和分析师在实际查数据中最先想到的写法,但是如果在目前Hive的query planner不是那么智能的情况下,想要更加快速的跑出结果,懂一点工具的内部机理也是必须的。









