【编程学习】Spark的RDD与任务调度原理

【编程学习】Spark的RDD与任务调度原理
6YoungSpark算子
要了解Spark中任务调度的基本原理,首先要了解一下Spark中算子的类型有哪些。
Spark算子分类
- 1.Transformation(转换算子) 它会在一个已经存在的 RDD 上创建一个新的 RDD,这也使得RDD之间存在了血缘关系与联系。这种算子用于从一个RDD转换成另一个RDD,它可以被用来创建新的RDD,也可以被用来转换已有的RDD。它们提供了一种通用的方法来完成RDD的转换,如map、filter、groupByKey等。
- 2.Action(动作算子) 执行各个分区的计算任务, 结果返回到 Driver 中。它们用于从一个RDD中收集数据,或者从一个RDD中计算结果,如collect、reduce、count等。行动算子可以基于RDD的转换算子的结果来进行计算,也可以基于一组RDD来进行计算。
Spark算子特点
- 1.Spark 中所有的 Transformations 是 惰性 的, 不会立即执行获得结果. 只会记录在数据集上要应用的操作.当需要返回结果给 Driver 时, 才会执行这些操作, 这个特性叫做 惰性求值
- 2.每一个 Action 运行的时候, 所关联的所有 Transformation RDD 都会重新计算。
常见的转换算子汇总
map算子:Map 将RDD的数据进行以一对一的关系转换成其他形式 输入分区与输出分区一对一
flatMap算子:flatMap算子的作用是将一行数据拆分成多个元素,并将所有元素放在一个新的集合中,返回一个新的RDD。它与map算子的区别在于,map算子只是将一行数据拆分成一个元素,并将其放在新的集合中;而flatMap算子可以将一行数据拆分成多个元素,并将所有元素放在一个新的集合中。
filter算子:spark中的filter算子用于对RDD中的每个元素应用一个函数,根据函数的返回值是true还是false来决定是否将该元素放入新的RDD中。
mapPartitions算子:map算子是一对一的操作,会将一个RDD中的每一个元素都映射到另一个RDD中;而mapPartitions算子是一对多的操作,它会将一个RDD中的每一个分区都映射到另一个RDD中,每个分区中的元素会被一次性处理,减少了操作次数,提高了处理效率。
reduceByKey算子:reduceByKey算子是spark中用于对pairRDD中key相同的元素进行聚合的算子。
groupByKey算子:groupByKey是Spark中的一个重要的转换操作,它的作用是对每个key对应的元素进行分组,然后将分组后的结果以key-value的形式返回,
sample算子:sample算子是spark中用来从一个RDD中抽样的算子,它可以根据指定的比例或数量从RDD中抽取一部分样本出来,可以用来做数据探索、模型开发等。
sortBy 算子:sortBy 算子是将RDD中的元素按照指定的规则排序,其返回类型为排序后的RDD
常见的行动算子汇总
reduce 算子:reduce 先聚合分区内数据,再聚合分区间数据
collcet算子:collcet 先将结果数据集以数组Array的方式返回
count算子:count 返回RDD的元素个数
take算子:take 返回RDD的前n个元素所组合而成的数组
foreach算子:foreach 遍历RDD中的元素
涉及Shuffle操作的算子
在Spark的算子中,有很多会导致数据进行重分区,也就是Shuffle操作,主要是以下三类算子:
- repartition类的操作:比如repartition、repartitionAndSortWithinPartitions、coalesce等,一般会shuffle,因为需要在整个集群中,对之前所有的分区的数据进行随机,均匀的打乱,然后把数据放入下游新的指定数量的分区内。
- byKey类的操作:比如reduceByKey、groupByKey、sortByKey等;byKey类的操作:因为你要对一个key,进行聚合操作,那么肯定要保证集群中,所有节点上的,相同的key,一定是到同一个节点上进行处理。
- join类的操作:比如join、cogroup等join类的操作;两个rdd进行join,就必须将相同join key的数据,shuffle到同一个节点上,然后进行相同key的两个rdd数据的笛卡尔乘积。
这种算子对于Spark任务调度与分配至关重要。
DAGScheduler
DAGScheduler核心职责,是把计算图 DAG 拆分为执行阶段 Stages,Stages 指的是不同的运行阶段,同时还要负责把 Stages 转化为任务集合 TaskSets,也就是把“建筑图纸”转化成可执行、可操作的“建筑项目”。
用一句话来概括从 DAG 到 Stages 的拆分过程,那就是:以 Actions 算子为起点,从后向前回溯 DAG,以 Shuffle 操作为边界去划分 Stages。
以 Word Count 为例,提到 Spark 作业的运行分为两个环节,第一个是以惰性的方式构建计算图,第二个则是通过 Actions 算子触发作业的从头计算:
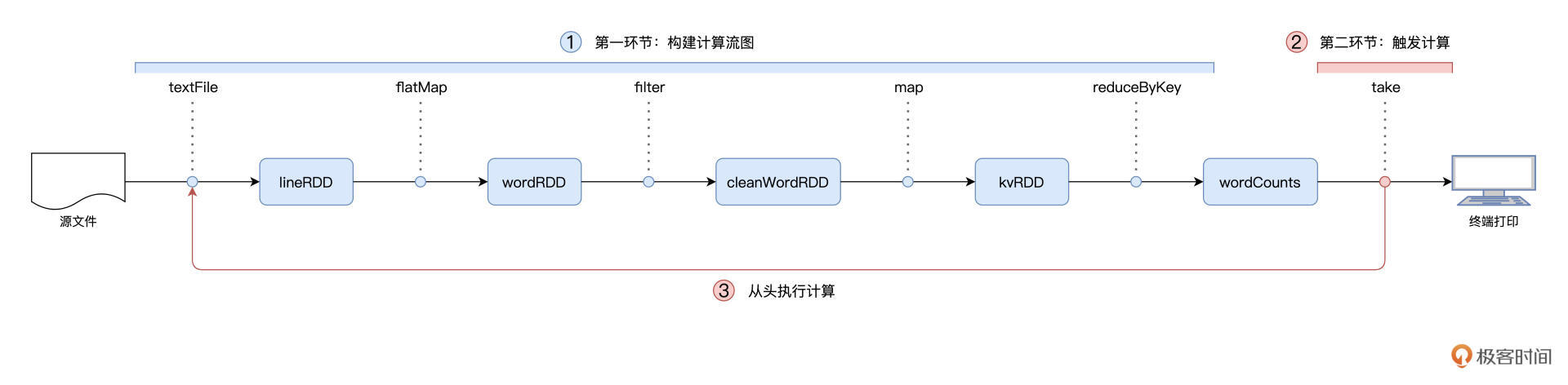
对于图中的第二个环节,Spark 在实际运行的过程中,会把它再细化为两个步骤。第一个步骤,就是以 Shuffle 为边界,从后向前以递归的方式,把逻辑上的计算图 DAG,转化成一个又一个 Stages。
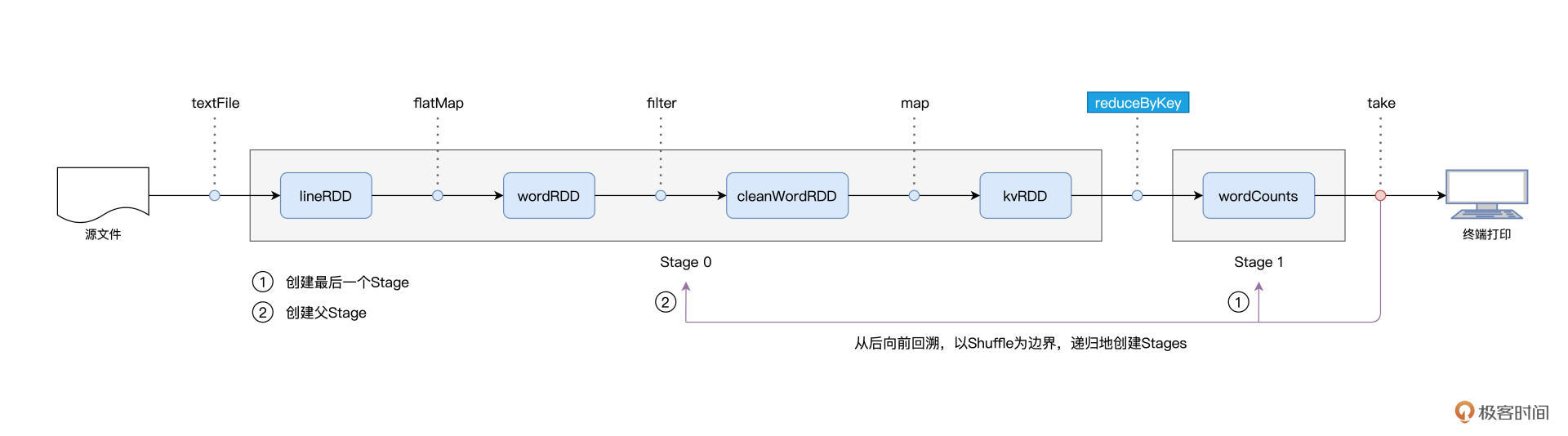
还是以 Word Count 为例,Spark 以 take 算子为起点,依次把 DAG 中的 RDD 划入到第一个 Stage,直到遇到 reduceByKey 算子。由于 reduceByKey 算子会引入 Shuffle,因此第一个 Stage 创建完毕,且只包含 wordCounts 这一个 RDD。接下来,Spark 继续向前回溯,由于未曾碰到会引入 Shuffle 的算子,因此它把“沿途”所有的 RDD 都划入了第二个 Stage。
在 Stages 创建完毕之后,就到了触发计算的第二个步骤:Spark从后向前,以递归的方式,依次提请执行所有的 Stages。
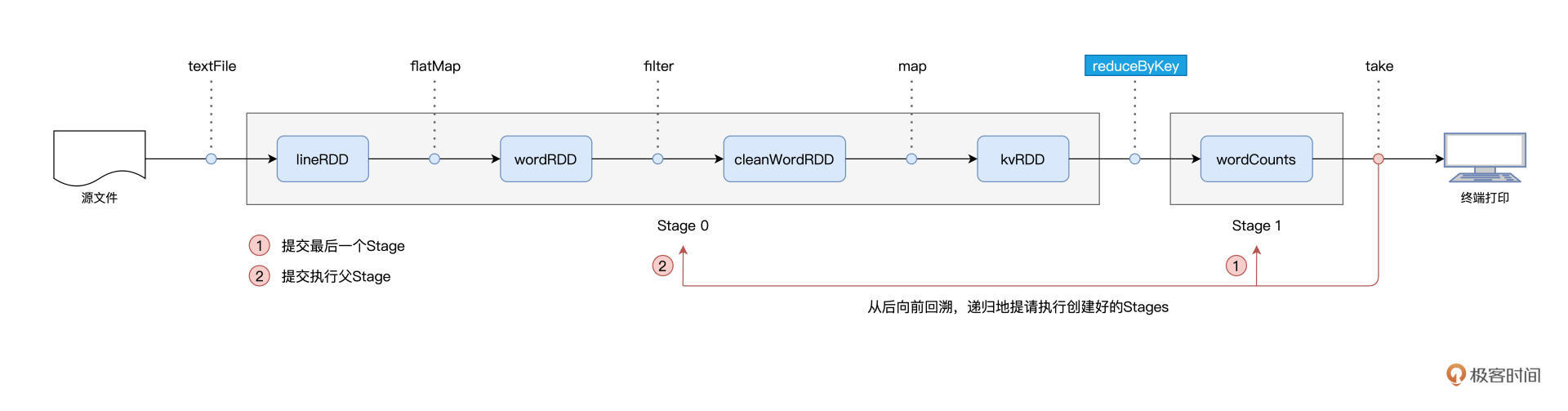
具体来说,在 Word Count 的例子中,DAGScheduler 最先提请执行的是 Stage1。在提交的时候,DAGScheduler 发现 Stage1 依赖的父 Stage,也就是 Stage0,还没有执行过,那么这个时候它会把 Stage1 的提交动作压栈,转而去提请执行 Stage0。当 Stage0 执行完毕的时候,DAGScheduler 通过出栈的动作,再次提请执行 Stage 1。
对于提请执行的每一个 Stage,DAGScheduler 根据 Stage 内 RDD 的 partitions 属性创建分布式任务集合 TaskSet。TaskSet 包含一个又一个分布式任务 Task,RDD 有多少数据分区,TaskSet 就包含多少个 Task。换句话说,Task 与 RDD 的分区,是一一对应的。
汇总一下,DAGScheduler 的主要职责有三个:
- 根据用户代码构建 DAG;
- 以 Shuffle 为边界切割 Stages;
- 基于 Stages 创建 TaskSets,并将 TaskSets 提交给 TaskScheduler 请求调度。
TaskScheduler
TaskScheduler的核心职责是,给定SchedulerBackend提供的资源,遴选出最合适的任务并派发出去。而这个遴选的过程,就是任务调度的核心所在,如下图所示:
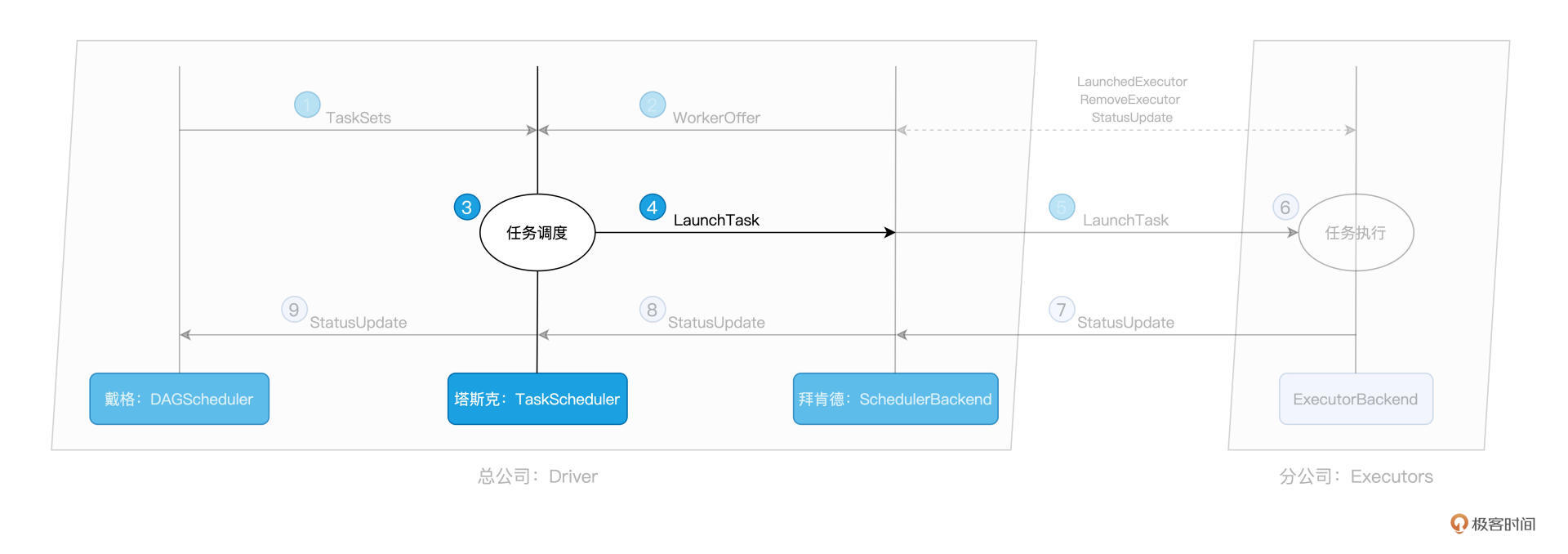
举例来说,当我们调用 textFile API 从 HDFS 文件系统中读取源文件时,Spark 会根据 HDFS NameNode 当中记录的元数据,获取数据分区的存储地址,例如 node0:/rootPath/partition0-replica0,node1:/rootPath/partition0-replica1 和 node2:/rootPath/partition0-replica2。
那么,DAGScheduler 在为该数据分区创建 Task0 的时候,会把这些地址中的计算节点记录到 Task0 的 locs 属性。
如此一来,当 TaskScheduler 需要调度 Task0 这个分布式任务的时候,根据 Task0 的 locs 属性,它就知道:“Task0 所需处理的数据分区,在节点 node0、node1、node2 上存有副本,因此,如果 WorkOffer 是来自这 3 个节点的计算资源,那对 Task0 来说就是投其所好”。
Spark 调度系统的核心思想,是“数据不动、代码动”。也就是说,在任务调度的过程中,为了完成分布式计算,Spark 倾向于让数据待在原地、保持不动,而把计算任务(代码)调度、分发到数据所在的地方,从而消除数据分发引入的性能隐患。毕竟,相比分发数据,分发代码要轻量得多。
像上面这种定向到计算节点粒度的本地性倾向,Spark 中的术语叫做 NODE_LOCAL。除了定向到节点,Task 还可以定向到进程(Executor)、机架、任意地址,它们对应的术语分别是 PROCESS_LOCAL、RACK_LOCAL 和 ANY。
对于倾向 PROCESS_LOCAL 的 Task 来说,它要求对应的数据分区在某个进程(Executor)中存有副本;而对于倾向 RACK_LOCAL 的 Task 来说,它仅要求相应的数据分区存在于同一机架即可。ANY 则等同于无定向,也就是 Task 对于分发的目的地没有倾向性,被调度到哪里都可以。不难发现,从 PROCESS_LOCAL、NODE_LOCAL、到 RACK_LOCAL、再到 ANY,Task 的本地性倾向逐渐从严苛变得宽松。TaskScheduler 接收到 WorkerOffer 之后,也正是按照这个顺序来遍历 TaskSet 中的 Tasks,优先调度本地性倾向为 PROCESS_LOCAL 的 Task,而 NODE_LOCAL 次之,RACK_LOCAL 为再次,最后是 ANY。
SchedulerBackend
SchedulerBackend的核心职责,就是实时汇总并掌握机器的计算资源状况。对于集群中可用的计算资源,SchedulerBackend 用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态。
这里的 ExecutorDataMap 是一种 HashMap,它的 Key 是标记 Executor 的字符串,Value 是一种叫做 ExecutorData 的数据结构。ExecutorData 用于封装 Executor 的资源状态,如 RPC 地址、主机地址、可用 CPU 核数和满配 CPU 核数等等,它相当于是对 Executor 做的“资源画像”。
SchedulerBackend 与集群内所有 Executors 中的 ExecutorBackend 保持周期性通信,双方通过 LaunchedExecutor、RemoveExecutor、StatusUpdate 等消息来互通有无、变更可用计算资源。拜肯德正是通过这些小弟发送的“信件”,来不停地更新自己手中的那本小册子,从而对集团人力资源了如指掌。
总结回顾
具体说来,任务调度分为如下 5 个步骤:
1、DAGScheduler 以 Shuffle 为边界,将开发者设计的计算图 DAG 拆分为多个执行阶段 Stages,然后为每个 Stage 创建任务集 TaskSet
2、SchedulerBackend 通过与 Executors 中的 ExecutorBackend 的交互来实时地获取集群中可用的计算资源,并将这些信息记录到 ExecutorDataMap 数据结构
3、与此同时,SchedulerBackend 根据 ExecutorDataMap 中可用资源创建 WorkerOffer,以 WorkerOffer 为粒度提供计算资源。
4、对于给定 WorkerOffer,TaskScheduler 结合 TaskSet 中任务的本地性倾向,按照 PROCESS_LOCAL、NODE_LOCAL、RACK_LOCAL 和 ANY 的顺序,依次对 TaskSet 中的任务进行遍历,优先调度本地性倾向要求苛刻的Task。
5、被选中的 Task 由 TaskScheduler 传递给 SchedulerBackend,再由 SchedulerBackend 分发到 Executors 中的 ExecutorBackend。Executors 接收到 Task 之后,即调用本地线程池来执行分布式任务。













